If you have spent any time in enterprise AI in 2025, you have heard the acronym RAG so often it has lost meaning. Ask five engineers what it stands for and you will get five correct definitions and five wildly different ideas about what it actually involves. This guide cuts through the noise.
RAG — Retrieval-Augmented Generation — is the most widely deployed LLM pattern in production enterprise software today. Understanding it properly is the difference between building AI systems that work reliably and spending months debugging why your chatbot confidently gives the wrong answer.
What is RAG?
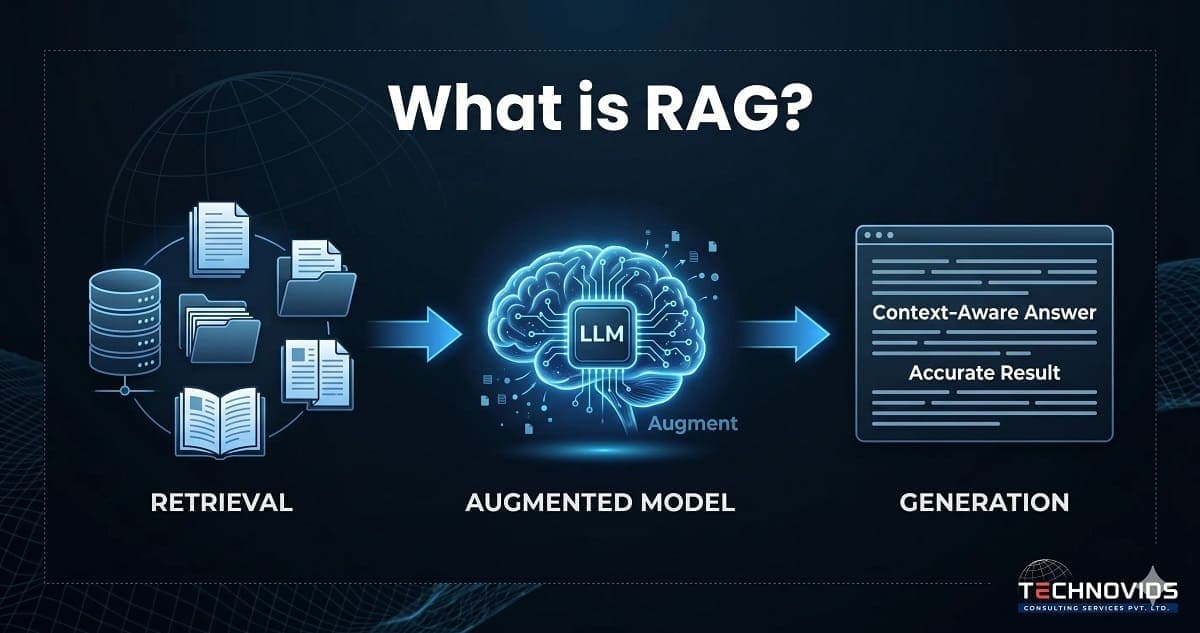
Retrieval-Augmented Generation (RAG) is an AI architecture that connects a large language model to an external knowledge source so it can answer questions using your specific data, not just its training data.
Here is the core problem RAG solves. An LLM like GPT-4 or Claude was trained on data up to a cutoff date. It knows nothing about your company's internal policies, your product documentation, last quarter's financial results, or the contract you signed last week. If you ask it a question about any of these things, it either makes something up (hallucination) or tells you it doesn't know.
RAG solves this by splitting the problem in two. Before the LLM generates an answer, a retrieval system finds the relevant documents, passages, or data records from your knowledge base and injects them into the prompt. The LLM then generates its answer based on the retrieved content — grounded in your actual data, not its training weights.
The result: an AI system that can answer questions about your refund policy, your engineering runbooks, your HR guidelines, or your product specifications — accurately, and without retraining the model.
How RAG Works: Step by Step
A production RAG pipeline has five stages. Understanding each one is critical because failures at any stage compound downstream.
1. Document ingestion and chunking
Your source data — PDFs, Word documents, database records, web pages — is loaded and split into chunks. The chunking strategy is one of the most consequential decisions in RAG design. Naive fixed-size chunking (split every 500 tokens) destroys context at arbitrary points. Better strategies use semantic boundaries: paragraph-aware splitting, markdown-heading-aware splitting for structured documents, or sentence-level chunking with overlap.
2. Embedding
Each chunk is converted into a numerical vector — an embedding — using an embedding model. The embedding captures the semantic meaning of the text. Chunks about similar topics end up close together in vector space, regardless of exact wording. Popular embedding models include OpenAI's text-embedding-3-small, Cohere's embed-v3, and open-source options like BGE-large and sentence-transformers.
3. Indexing in a vector database
The embeddings are stored in a vector database — Pinecone, Weaviate, ChromaDB, FAISS, or Qdrant — alongside the original text chunks. The vector database enables fast approximate nearest-neighbour (ANN) search: given a query embedding, find the N most semantically similar chunks in milliseconds.
4. Retrieval
When a user submits a query, the query is embedded using the same model as the documents. The vector database finds the top-K most similar chunks. Basic RAG stops here and passes these chunks to the LLM. Production RAG adds a reranking step — using a cross-encoder to score and re-order retrieved chunks for true relevance, not just vector proximity — and may use hybrid search (combining dense vector search with BM25 sparse keyword search) for better precision.
5. Generation
The retrieved chunks are injected into the prompt alongside the user's question. The LLM generates a response grounded in the retrieved context. A well-designed prompt instructs the LLM to answer only based on what was retrieved and to say "I don't have information on this" when the relevant context wasn't found.
RAG vs Fine-Tuning: Which Should You Use?
This is the question we get most often in corporate training sessions. The honest answer: for most enterprise use cases, RAG is the right choice, and fine-tuning is a distraction.
Fine-tuning modifies the LLM's weights by training it on your data. It makes sense when you need the model to behave differently — adopt a specific tone, respond in a domain-specific format, or handle a specialised task the base model handles poorly. It requires a labelled dataset, compute budget, and time. And crucially: fine-tuned models go stale. When your data changes, you retrain.
RAG keeps the base model unchanged and retrieves context at inference time. It is cheaper (no GPU training cost), faster to update (add new documents to the index without any retraining), and auditable (you can inspect exactly which chunks were retrieved for any answer).
The rule of thumb: if your problem is "the model doesn't know our data," use RAG. If your problem is "the model knows the data but behaves wrong," consider fine-tuning. Most enterprise problems are the first kind.
RAG vs Keyword Search
Many teams already have search infrastructure — Elasticsearch, Solr, or a simple SQL LIKE query. The question is: why not just use that?
Keyword search is exact. It finds documents containing the words in the query. RAG retrieval is semantic. It finds documents with similar meaning, regardless of exact wording. A user asking "What is our leave policy for new parents?" will find the right policy even if the document uses the phrase "parental absence entitlement" — something keyword search would miss entirely.
Beyond retrieval, RAG synthesises. It doesn't just return a list of documents — it reads the retrieved content and generates a direct, natural-language answer. For knowledge workers who need answers, not document links, this is a significant quality improvement.
The practical question for most teams: RAG does not replace existing search infrastructure. It complements it. Your vector database handles semantic search; your existing tools handle structured queries and exact lookups. Production systems frequently use both.
Why Most RAG Projects Fail in Production
The LangChain quickstart tutorial gets you a working RAG chatbot in 20 minutes. Teams run it on sample PDFs and it looks impressive. Then they load their actual data — 10,000 internal documents, mixed formats, multiple languages, inconsistent structure — and everything breaks. Here is why.
Naive chunking destroys context. Splitting a 50-page policy document into 500-token chunks at arbitrary points means answers that require understanding two adjacent paragraphs will fail. The retrieved chunk contains half the relevant context.
Cosine similarity is not precision. Vector similarity retrieves semantically related content, but "related" is not "relevant." A query about sick leave might retrieve chunks about annual leave, parental leave, and leave policies in general — all similar, not all relevant. Without reranking, the LLM gets noisy context and produces noisy answers.
No evaluation harness. Teams ship RAG without measuring retrieval quality or generation faithfulness. Problems only surface when users complain. By then, the system is in production and diagnosing failures is painful. The RAGAS framework — which measures faithfulness, answer relevancy, context precision, and context recall — should be part of every RAG pipeline before deployment.
Silent quality degradation. As your document collection grows and changes, retrieval quality drifts. New documents may not be well-represented in the index. Old documents may no longer be accurate. Without monitoring, you don't know until users lose trust.
Building Your First RAG Pipeline
The minimal stack to get started: Python, LangChain (or LlamaIndex), an embedding model (OpenAI or a free alternative), and ChromaDB (local, no account needed). For production, swap ChromaDB for a managed vector database like Pinecone or Weaviate, add a reranker, and build an evaluation harness with RAGAS.
The learning progression that works:
- Week 1: Build a basic RAG pipeline over 10 PDFs. Get it working end-to-end.
- Week 2: Break it deliberately. Load messy data, ask edge-case queries, observe failures.
- Week 3: Fix the failures. Improve chunking, add metadata filtering, implement a reranker.
- Week 4: Add evaluation. Measure retrieval precision and generation faithfulness. Define your quality bar.
The developers who follow this pattern — build, break, fix, measure — consistently reach production quality faster than developers who try to build the perfect pipeline from the start.
Next Steps
If you want to learn RAG properly — not just the quickstart — there are two paths depending on your situation.
For individual developers: the AI Engineering Roadmap 2025 maps the full learning journey from Python to production RAG, agents, and MCP. Stage 3 covers RAG in depth with honest timelines and concrete milestones.
For developer teams: our Production AI Engineering corporate training covers RAG foundations through production deployment in a hands-on, project-based format. Teams leave with a working RAG system built on their own data — not a tutorial demo. Read more about our RAG training for developer teams in India.